Key Findings and Analysis
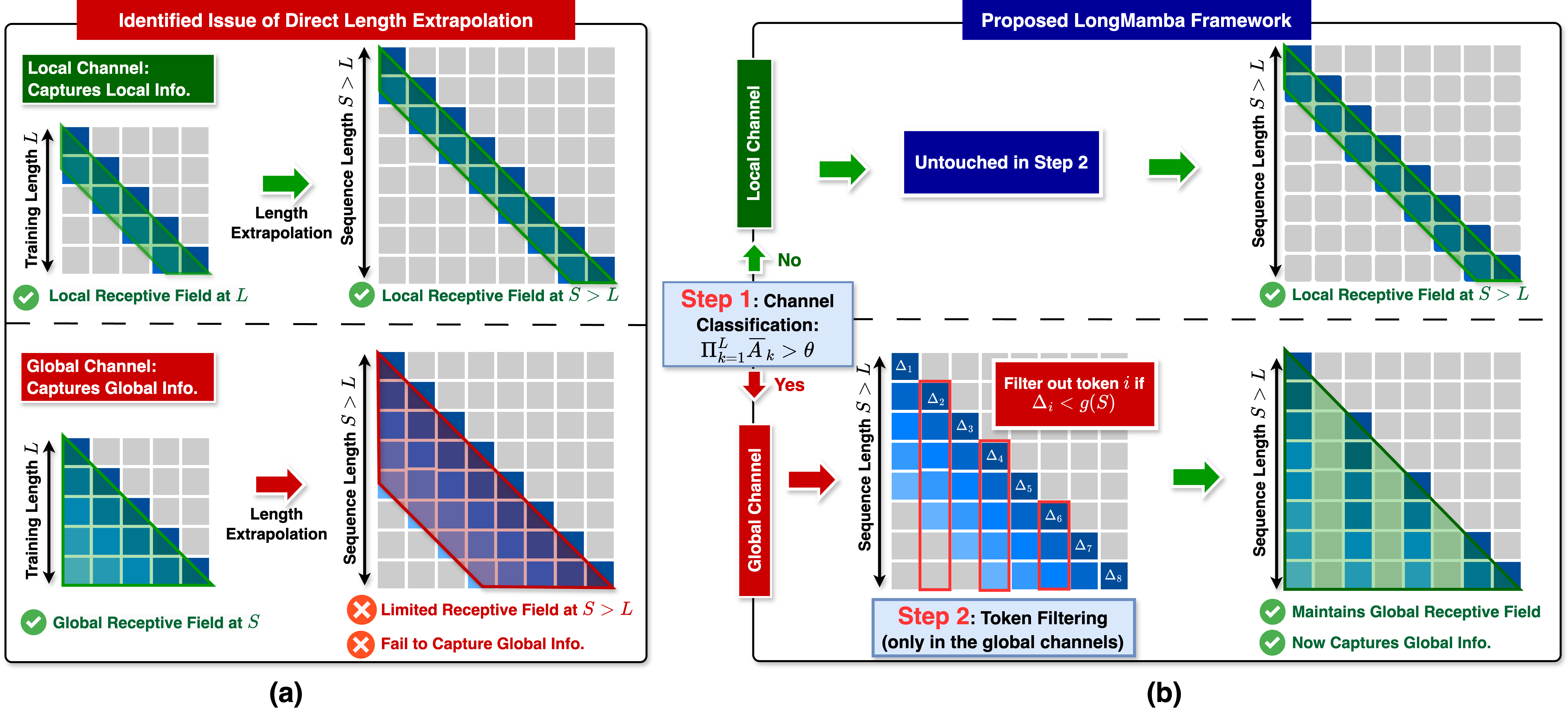
Figure 1: Visualization of the Mamba-130M model's attention map (log scale) of 5 sampled channels under (a) training sequence length (2,000 tokens) and (b) extended sequence length (16,000 tokens).
🔍 Finding 1: Hidden state channels in SSMs can be categorized into two classes, based on their receptive field lengths at training sequence length (Fig. 1(a)):
- Local channels: Channels exhibit receptive fields that are significantly shorter than the training sequence length, suggesting that these channels function like a convolution layer or a sliding window attention that captures localized information.
- Global channels: Channels with receptive fields that are comparable to the entire training sequence length, meaning the global channels learn to capture information globally from the entire sequence.
🔍 Finding 2: Global channels struggle to keep global attention coverage (global receptive field) at extended context lengths, as shown in Fig. 1(b), which could limit SSMs' capability for capturing and understanding long-context information.